この文書について
この文書は、技術評論社刊『WEB+DB PRESS Vol.22』に執筆した記事を技術評論社の 許可を得てWWWで公開しているものです。
このWWW版は校正前の原稿を元にしている点、WWW公開後に必要があれば修正する点で、雑誌版の文章とは異なる部分があります。また、図表も雑誌版とは異なります。 予めご了承ください。
また、この文章が対象しているのはMySQL 4.0系なので、最新のリリース版と比べると説明不足な点などが多々あると思います。
レプリケーションの基本をおさえるには、この文書はまだ有益だと思いますが、設定レベルの説明は最新のドキュメントを参照するようにしてください。
なお、MySQL 5.1をターゲットとした、障害発生時のリカバリプランについての記事もありますので、レプリケーション構成を組む際には、こちらも参考になると思います。


このページの末尾には参考書籍も紹介していますので、こちらもあわせて参照していいただくといいと思います。
はじめに
MySQLでレプリケーションがサポートされたのは2000年5月にリリースされた3.23.15からと古く、4.0でその仕組みが一部、見直されたものの、比較的「枯れた」機能であり、筆者の感触では安定性や信頼性は十分に高いといえるレベルに達しています。
また、MySQL本体にレプリケーションの機能が実装されているのも特色で、レプリケーションのために外部アプリケーションを用意する必要もなく、設定も比較的簡単なので手軽にレプリケーション構成を組むことが可能です。
本章では、MySQLのレプリケーションの特徴と仕組みを紹介した後、レプリケーションのセットアップ、状態確認、トラブルシューティングといったより実践的な内容の説明をします。
なお、本章の動作確認は、次の環境にて行いました。
- OS: Linux (Fedora Core 2)
- MySQL: 4.0.20 (MySQL AB提供のrpmパッケージ)
レプリケーション概観
レプリケーションとは
一般にレプリケーションとは、他のサーバにデータベースを複製することをいいます。複製はLANやインターネットなどネットワークを経由して行われるので、物理的に離れた場所にあるサーバへデータベースをレプリケートすることもできます。
複製方法の種類
複製の方法には同期と非同期の2種類があります。
同期複製の場合は、レプリケーションを構成する全てのサーバで常に全く同じデータが保持されることが保証されますが、一方でデータの同期を取るために他のサーバの応答を待つ必要があるので、サーバの台数が多くなる程、全体の応答性が低下する可能性があります。
逆に非同期複製は、サーバ台数の増加によるパフォーマンスの低下はほとんどありませんが、短い時間で観測した場合、サーバ間でデータの同期が保証されないという問題があります。
構成の種類
主なレプリケーションの構成にはマスタスレーブとマルチマスタがあります。
マスタスレーブ構成は、更新系のクエリを受け付けるのはマスタサーバのみで、スレーブはマスタから伝搬されたもの以外の更新処理は行いません。
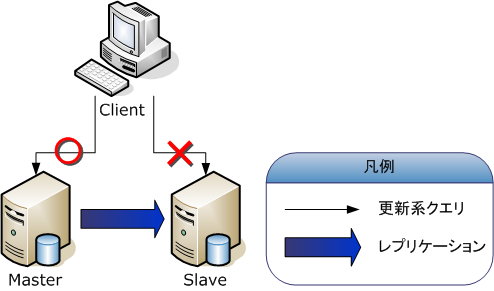
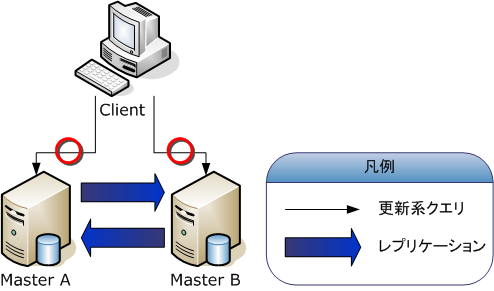
マルチマスタは、どのサーバでも更新系のクエリを受け付けるような構成です。
複製方法と構成の組み合わせ
代表的なレプリケーションの形態は、複製の方法と構成の組み合わせで4通り考えられますが、非同期マスタスレーブが悪く、同期マルチマスタがよいというものではなく、それぞれに一長一短がありますので、要件によって使い分けましょう。
MySQLのレプリケーションの特徴
続いてMySQLのレプリケーションの特徴を見ていきましょう。
MySQLのレプリケーションは、一方向の非同期マスタスレーブ型のレプリケーションで、1つのマスタサーバに対して1つ以上のサーバがスレーブとなることができます。
マスタはスレーブのホスト名や更新状況などのスレーブの情報は一切保持しておらず、単純に接続してきたスレーブに要求された更新情報を渡すだけです。一方、スレーブはマスタのホスト名や更新状況を記憶しているので、ネットワークトラブルなどでマスタとの通信が一時的にとだえても、復旧すれば中断したところから自動的に再開します。
MySQLのレプリケーションでできること
負荷分散
負荷分散機を経由して、スレーブサーバ群に参照系のクエリを負荷分散することができます。ただし、前述した通りMySQLのレプリケーションは非同期なので注意が必要です。具体的には、全く更新しないテーブル、もしくは、クライアントアクセスがない夜間のバッチ処理でしか更新しないマスタテーブルに対する参照系のクエリのような、スレーブへの伝搬の遅延が問題にならないクエリは負荷分散することができますが、ユーザ情報の更新をマスタに対して行った直後にスレーブにそのユーザの情報を問い合わせるような場合には、得られた結果が食い違う危険性があります。
高可用性
マスタに何らかの障害が発生してサービス不能になった場合、スレーブが代わりにサービスをすることにより、短いダウンタイムでサービスを再開することができます。
しかし残念ながら、マスタの切り替えを自動で行う機能はMySQL本体には実装されていません(注1)ので、切り替え処理は手動で行うか、切り替えプログラムを自作する必要があります。
とはいえ、バックアップをレストアして復旧する方法に比べれば、かなり短い時間で復旧できるはずです。
バックアップ
データの整合性を保ちつつバックアップを取るには、MySQLを停止してオフラインバックアップを行うか、書き込みロックをしてオンラインバックアップを取る必要があります(注2)。しかしレプリケーション構成ならば、スレーブのデータがバックアップデータとなりますし、フルバックアップを取る場合はスレーブのデータをバックアップすれば、マスタが提供しているサービスには一切影響なくバックアップを取ることができます。
また、物理的に離れた場所にあるマスタとスレーブでレプリケートすれば、ディザスタリカバリも容易となります。
InnoDB形式の場合、商用のInnoDB Hot Backupを使え ばオンラインのままテーブルをロックすることなくバッ クアップできます。日本では(株)ソフトエイジェンシー が販売代理店となっています。
http://www.innodb.com/index.php
http://www.softagency.co.jp/mysql/InnoDB.html
MySQLのレプリケーションでできないこと
更新系の負荷分散
更新系クエリの負荷を複数のサーバに分散することはできません。
まず、単純なマスタスレーブ構成ではマスタは1つしかないので、更新系のクエリはこのマスタに集中させるしかありません。
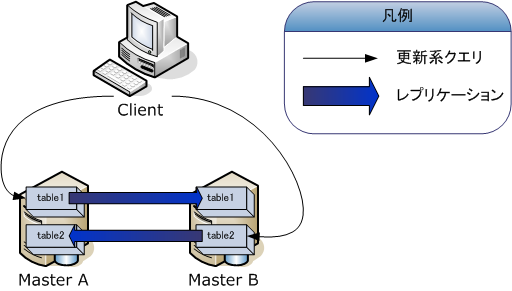
次にデュアルマスタ構成を考えてみます。MySQLのレプリケーションでは、スレーブは他のスレーブのマスタになることができるので図3のようなデュアルマスタ構成にすることができます。しかし、マスタ間で更新処理が競合する可能性があるので、より上位のレイヤで更新対象となるテーブルごとにクエリの発行先のマスタを区別するなど工夫が必要です。例えばユーザー情報の更新はマスタAへ、商品情報の更新はマスタBへ、というようにです。
これで更新系のクエリを分散することができるようになるわけですが、実は負荷の分散にはなっていません。なぜなら、マスタAに対して行われた更新処理は、レプリケーションによりマスタBでも実行されるので、結局、両方のマスタで更新系のクエリが実行されることになり、更新系クエリの受け付けの分散はできても更新処理の負荷を分散したことにはならないからです。
スレーブの負荷軽減
前節の更新系の負荷分散と同じように、更新系のクエリはレプリケートされてスレーブでも処理されるので、更新系のクエリが多い場合はスレーブでもその分の負荷はかかります。
レプリケーションのしくみ
MySQLのレプリケーションがどのように行われているのか、もう少し詳しく見てみましょう。まずは全体の流れを概観して、続いて関連するスレッド(注3)とファイルについて解説します。
ここでの『スレッド』とは、mysqldの内部的な一連の 処理の単位と考えてください。
レプリケーションの流れ
マスタとスレーブのやり取りは次のよう行われています。
- マスタで処理された更新系のクエリが逐次、マスタのバイナリログに記録される。
- スレーブのI/OスレッドがマスタのBinlog Dumpスレッドに接続する。
- マスタのBinlog Dumpスレッドは、バイナリログの内容をどんどん送信する。Binlog Dumpスレッドはこの処理を繰り返す。
- スレーブのI/Oスレッドは、受け取ったマスタのバイナリログをスレーブ内に保存する。これをリレーログと呼ぶ。I/Oスレッドはこの処理を繰り返す。
- スレーブのSQLスレッドは、リレーログからクエリを読み取って実行する。SQLスレッドはこの処理を繰り返す。
スレッド
スレーブではI/OとSQLの2つのスレッドが稼働しています。I/Oスレッドはひたすらマスタから得たデータをリレーログに記録し、SQLスレッドはひたすらリレーログを読み取ってクエリを実行します。
なぜこのようにデータの取得と実行が分離されているのでしょうか。実はMySQL 3.23のレプリケーションでは、スレーブでは1つのスレッドしかなく、データの取得と実行の両方を行っていました。この場合、データの取得→実行→取得…というように交互に処理されるため、時間のかかるクエリをスレーブで実行している間はマスタからのデータの取得が停止してしまい、結果的にマスタに追い付くのに時間がかかってしまいます。
このような問題を解消するため、MySQL 4.0.2から2つのスレッドに分割されました。また、マスタから得たデータをスレーブ内にリレーログとして一旦、保存することにより、スレーブのSQLスレッドの処理が遅れている間にマスタがダウンしたとしても、I/Oスレッドがマスタがダウンする直前までのデータをリレーログとしてローカルに保存しているので、暫く待てばスレーブはマスタがダウンする直前と同じデータを持つ状態になります。
master.info、relay-log.info
スレーブにはレプリケーションの状態を保持するファイルが2つ作られます。master.infoとrelay-log.infoです。
master.infoには、マスタのホスト名、接続ユーザ名、マスタのバイナリログのファイル名とスレーブのI/Oスレッドがどこまでマスタのバイナリログを取得したかなどが記録され、I/Oスレッドによって更新されます。これはスレーブがレプリケーションを再開する際に、どこまでマスタのバイナリログを処理したか確認するために使われます。
relay-log.infoには、リレーログのファイル名や位置情報などが記録され、SQLスレッドによって更新されます。master.infoと同じく、レプリケーションを再開する際に、リレーログをどこまで処理したか確認するために使われます。この2つのファイルに記録されている情報は、後述するSHOW SLAVE STATUS文で見ることができます。いずれのファイルも、原則的には管理者がファイルを直接書き換える必要はなく、情報を操作するときはCHANGE MASTER TO文などを使います。
バイナリログ、リレーログ
マスタにはバイナリログ、スレーブにはリレーログと呼ばれるファイルが保存されます。
バイナリログにはデータを更新する処理のみが記録され、参照系のクエリなどは記録されません。レプリケーションの他にも、フルバックアップからの更新分のみのバックアップという用途にも使われます。
バイナリログは、その名の通りテキスト形式ではないので直接エディタで開いて見ることはできませんが、mysqlbinlogコマンドでテキスト形式に変換することができます。
リレーログは、スレーブのI/Oスレッドがマスタのバイナリログをスレーブ側に保存したものです。ですのでその内容はバイナリログと同じです。また、バイナリログと違い、必要がなくなるとSQLスレッドによって自動的に削除されるので、手動で削除する必要はありません。
レプリケーションのセットアップ
レプリケーションについての説明はこのぐらいにして、実際にレプリケーションをセットアップしてみましょう。
まずはレプリケーションに必要な条件を確認して、続いて新規にセットアップする場合と既存のサーバをレプリケーション構成にする場合のそれぞれについて、具体的に手順をみていきます。
レプリケーションの条件など
- マスタは複数のスレーブを持つことができる。
ひとつのマスタの配下には、複数のスレーブを配置することができます。
- スレーブはマスタをただ一つ持つことができる。
スレーブは複数のマスタとレプリケートすることはできません。ただし、スレーブは他のサーバのマスタとなることはできます。
- 全てのマスタ、スレーブの中で一意なserver-idを指定しなければならない。
server-idは、レプリケーション構成内のサーバを識別するためのもので、互いに異なる値を指定する必要があります。指定しない場合は1もしくは2になりますが、混乱を防ぐために明示的に指定しましょう。万全を期すならば、省略時の値である1、2以外の値を指定した方がよいと思います。
- マスタはバイナリログを出力しなければならない。
更新系のクエリをスレーブに伝えるため、マスタではバイナリログを有効にする必要があります。
新規のサーバでセットアップ
では新規にレプリケーション構成をセットアップする手順を見ていきます。ここでは、MySQLをインストールした直後で、バイナリログが有効になっていない状況を想定しています。
レプリケーション用ユーザの作成
スレーブがマスタに接続するためのユーザをマスタに作成します。最低限、与えなければならないのはREPLICATION SLAVE権限だけです。このユーザはレプリケーション専用とし、他の権限は与えないようにした方がよいでしょう。
例えば、ユーザ名『repl』、パスワード『qa55wd』で、10.6.25.0/24のネットワークにスレーブが存在する場合は、図4のようにマスタで実行します。
mysql> GRANT REPLICATION SLAVE ON *.* TO repl@'10.6.25.0/255.255.255.0' IDENTIFIED BY 'qa55wd'; Query OK, 0 rows affected (0.01 sec)
マスタのデータをスレーブにコピー
マスタのデータを全部スレーブにコピーします。いろいろな方法が考えられますが、ここではtarコマンドを使ってファイルシステム上のファイルを丸ごとコピーする方法を説明します。
まずはマスタでの作業です。mysqldが稼働中ならば停止します。
# /etc/init.d/mysql stop Killing mysqld with pid 24878 Wait for mysqld to exit done
データファイルをtarでまとめて、scpなどでスレーブにコピーします。
# cd /var/lib/mysql # tar cpf /var/tmp/mysql.tar . # scp /var/tmp/mysql.tar myslave:/var/tmp/mysql.tar
次はスレーブでの作業です。もしスレーブでmysqldが稼働中であれば停止して、先程マスタからコピーしたtarファイルをMySQLのデータディレクトリと入れ替えるように展開します。
# cd /var/lib/mysql # rm -fr * # tar xpf /var/tmp/mysql.tar
マスタの設定
バイナリログとserver-idの設定のため、図5をマスタの/etc/my.cnfに追加します。
[mysqld] log-bin server-id=10
設定を追加したらmysqldを起動します。バイナリログが有効になったかは、データディレクトリに『ホスト名-bin.001』と『ホスト名-bin.index』というファイルができていることで確認できます(図6)。また、SHOW MASTER STATUS文でも確認することができます(図7)。
# ls -l /var/lib/mysql/*-bin.* -rw-rw---- 1 mysql mysql 79 Jul 5 16:07 /var/lib/mysql/mymaster-bin.001 -rw-rw---- 1 mysql mysql 19 Jul 5 16:07 /var/lib/mysql/mymaster-bin.index
mysql> SHOW MASTER STATUS; +------------------+----------+--------------+------------------+ | File | Position | Binlog_do_db | Binlog_ignore_db | +------------------+----------+--------------+------------------+ | mymaster-bin.001 | 359 | | | +------------------+----------+--------------+------------------+
server-idは、図8のようにSHOW VARIABLES文で確認できます。
mysql> SHOW VARIABLES LIKE 'server\_id'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 10 | +---------------+-------+
スレーブの設定
続いてスレーブで、server-idとレプリケートするマスタを指定します。
server-idは、マスタのserver-idと異なり、他にスレーブがいる場合はそれらとも異なる値にします。ここではスレーブのserver-idを11に設定します。
マスタの情報として、マスタのホスト名、接続ユーザとそのパスワードを設定します。ここではマスタのホスト名は『mymaster』とし、接続ユーザの情報は先立ってマスタで作成したものを使います。
まとめると、スレーブの/etc/my.cnfに追加するものは図9のようになります。
[mysqld] server-id=11 master-host=mymaster master-user=repl master-password=qa55wd
追加したらmysqldを起動します。スレーブのエラーログファイルに図10のように出力されていればレプリケーション成功です。
040705 16:21:31 Slave I/O thread: connected to master 'repl@mymaster:3306', replication started in log 'FIRST' at position 4
試しにマスタに対して更新系のクエリを発行して、スレーブに反映されるか確認してみましょう。
既存のサーバを使ってセットアップ
次に、稼働中のサーバをマスタとして、新規にスレーブを追加してレプリケーション構成にする方法を見ていきましょう。
稼働中のサーバを使ってレプリケーション構成にする場合は、新規の場合と比較して手順が繁雑になります。ポイントは、『スナップショット』と『位置を指定してスレーブを開始』です。ここで説明することは、既にレプリケーション構成になっているサーバ群に更にスレーブを追加する場合や、障害発生時のリカバリにも応用できるので、文章を読むだけでなく是非とも試験環境で自分の手を動かして確認して欲しいと思います。
さて、『スナップショット』という言葉が出てきましたが、本章では『ある時点の全データのバックアップとバイナリログの位置情報』をこの定義とします。
マスタの設定の確認
まずはマスタの状況などを確認します。レプリケーション用のユーザが存在しない場合は、前節と同じように作成します。
また、マスタでバイナリログとserver-idが設定されていることを確認してください。設定されていない場合は、前節を参照して設定しておきます。
スナップショットの取得
次にスナップショットをとります。具体的な取得方法を説明する前に、なぜスナップショットが必要なのか考えてみます。
レプリケーションを新たに開始する場合、マスタのデータのバックアップだけでは情報が足りません。なぜなら、データだけあってもマスタのバイナリログのどの時点からレプリケートを開始すればよいかスレーブにはわからないからです。新規セットアップの場合は、『いちばん初めの』バイナリログからレプリケート開始すればよかったので特にバイナリログの位置情報を意識する必要はありませんでしたが、既にバイナリログを出力しているサーバをマスタにする場合はそうはいきません。したがって、ある時点の全データとバイナリログの位置情報のセット、つまり、スナップショットがスレーブの開始には必要であるということになります。
ではそのスナップショットの具体的な取得方法です。
残念ながら、現状のMySQLではマスタからスナップショットをとるには、なんらかの方法で更新系のクエリが発生しない状態にしなければなりません(注4)。
前述の商用のInnoDB Hot Backupを使えばオンライン のままスナップショットを取得することができます。
ここでは更新系のクエリを停止するためにFLUSH文を使います。FLUSH TABLES WITH READ LOCK文を実行すると、UNLOCK TABLESを実行するまで参照系のクエリは実行ができますが、更新系のクエリは全てブロックされる状態になるので、この間にtarでデータを丸ごとコピーします。
それではやってみましょう。まず、ターミナルを2つ用意します。ターミナル1ではテーブルのロックを、ターミナル2ではtarコマンドでバックアップをとることにして、ターミナル1ではMySQLのrootユーザでマスタに接続しておき、ターミナル2ではマスタのサーバにログインしてOSのスーパーユーザになっておきます。
いきなりテーブルをロックする前に、できるだけ停止時間を短くすることを考えてみます。空きメモリが十分にある場合は、事前にtarコマンドを実行しておくと、ディスクキャッシュの効果で2回目の実行が早く終了する可能性が高いです。また、tarでコピーしながらパイプで繋いで別のサーバにコピーしたり、GNU tarの場合はtarアーカイブを作りながら圧縮することができますが、いずれもtarの完了を遅らせる要因となるので、ディスク残量が少ないなどの理由がなければ、単純にtarアーカイブを作るだけの方が停止時間を短くすることができます。
ではターミナル2で、ディスクキャッシュの効果を期待して予行演習のtarを実行します。
# cd /var/lib/mysql # tar cpf /var/tmp/mysql-snapshot.tar .
tarが完了したら、すかさずターミナル1でFLUSH文を実行します。ここから更新系のサービス停止となります。実行後、MySQLのプロンプトが現れますが、そのまま何も入力しないで放置します。ロックが外れてしますので、サーバから切断してはいけません。
mysql> FLUSH TABLES WITH READ LOCK; Query OK, 0 rows affected (0.00 sec) mysql>
ターミナル2で、先程実行したのと同じtarコマンドを再度実行します。場合によっては実行例のように、UNIX ドメインソケットファイルがコピーできないと警告が表示されますが、このファイルはスナップショットには必要ないので問題はありません。
# tar cpf /var/tmp/mysql-snapshot.tar . tar: ./mysql.sock: socket ignored
tarが完了したら、ターミナル1でSHOW MASTERSTATUS文を実行して、マスタのバイナリログの位置情報を確認します。しつこいようですが、この位置情報が重要ですので忘れないようにしっかり記録してください。
mysql> SHOW MASTER STATUS; +------------------+----------+--------------+------------------+ | File | Position | Binlog_do_db | Binlog_ignore_db | +------------------+----------+--------------+------------------+ | mymaster-bin.001 | 359 | | | +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec)
位置情報をメモしたら、UNLOCK TABLESを実行してロックを外します。これでサービス再開となります。
mysql> UNLOCK TABLES; Query OK, 0 rows affected (0.00 sec)
本文中ではスナップショットをとるのにFLUSH文を使 いましたが、mysqldを終了して更新が発生しない状態 を作る方法でも問題ありません。
ただし、1つ注意があります。位置情報を知るには mysqldに接続しなければならないのですが、不用意に mysqldを立ち上げると更新系のクエリを受け付けてし まい、せっかくとったバックアップと位置情報がずれ てしまいます。ですので、場合にもよります が、--skip-networkingオプションつきでmysqldを起動 してネットワーク経由のクエリを受け付けないように するなどの対処が必要となります。
一方、FLUSH文の場合は、FLUSH文を実行した接続を 切断した場合もロックが外れてしまうので、手がすべっ てmysqlコマンドを終了してしまわないように気をつけ てください。また、ロック中に更新系のクエリを発行 した場合、すぐにエラーで返るのではなく、ロックが 外れるまで待たされる点にも注意が必要です。例えば 更新系のクエリを多数発行するウェブアプリケーショ ンの場合、クエリがブロックされるためウェブサーバ のプロセスがなかなか終了しなくなり、あっという間 にウェブサーバがサービス不能になる可能性がありま す。
スレーブの開始
続いてスレーブでの作業に移ります。スナップショットを保存しておけば、これから行うスレーブでの作業は失敗してもマスタに影響する事なく何度でもやり直せるので、リラックスしていきましょう。
新規のときと同じように、スナップショットをスレーブにコピーしてデータディレクトリに展開します。もし、スレーブでmysqldが稼働している場合は、停止してから展開します。
# /etc/init.d/mysql stop Killing mysqld with pid 1677 Wait for mysqld to exit. done # cd /var/lib/mysql # rm -fr * # tar xpf /var/tmp/mysql-snapshot.tar
展開したら、マスタではバイナリログやエラーログであったファイルなどはスレーブでは必要ないので削除します。
# cd /var/lib/mysql # rm -f マスタのホスト名-bin.??? マスタのホスト名-bin.index # rm -f マスタのホスト名.pid マスタのホスト名.err
次にスレーブの/etc/my.cnfを図11のように編集します。新規の時と同じようにserver-idの指定は必要ですが、master-hostなどはコメントアウトするなどして無効にしておきます。これは、mysqldが起動した後にマスタのバイナリログの位置情報をスレーブに教えたいので、まずはレプリケーションを無効にしてmysqld を起動するためです。
[mysqld] server-id=11 #master-host=mymaster #master-user=repl #master-password=qa55wd
/etc/my.cnfの編集が完了したらmysqldを起動します。
mysqldが起動したら、図12のCHANGE MASTER TO文を実行してマスタの情報を指定します。MASTER_HOST、MASTER_USER、MASTER_PASSWORDには新規のときと同じように、それぞれマスタのホスト名、接続ユーザ名、接続ユーザのパスワードを指定します。MASTER_LOG_FILEにはスナップショットをとったときのSHOW MASTER STATUSの『File』の値を、MASTER_LOG_POSには『Position』の値を指定します。
mysql> CHANGE MASTER TO
-> MASTER_HOST = 'mymaster',
-> MASTER_USER = 'repl',
-> MASTER_PASSWORD = 'qa55wd',
-> MASTER_LOG_FILE = 'mymaster-bin.001',
-> MASTER_LOG_POS = 359;
Query OK, 0 rows affected (0.06 sec)
続いて図13のようにSTART SLAVE文を実行します。実行直後から、スレーブとしてレプリケーションが開始されます。
mysql> START SLAVE; Query OK, 0 rows affected (0.01 sec)
レプリケーションが成功したら、/etc/my.cnfを編集してmaster-hostなどを有効にしておきましょう(図14)。実はCHANGE MASTER TOを実行した時点で、これらの情報はスレーブのmaster.infoファイルに保存されるので/etc/my.cnfでは指定しなくてもよいのですが、後日混乱しないようにmy.cnfに書いておいた方が無難でしょう。
[mysqld] erver-id=11 master-host=mymaster master-user=repl master-password=qa55wd
レプリケーションの状況確認
レプリケーションの状況を確認する方法をいくつか紹介します。これらはレプリケーションがうまくいかない原因の特定や状態監視に活用できるでしょう。
マスタの状況確認
まずはマスタの状況を確認するためのSQL文です。
SHOW MASTER STATUS
スナップショットをとるときにも使用した文です。図15のような出力が表示され、項目の内容は表1の通りです。
MySQLはデータベース単位でバイナリログに記録する/しないの指定ができ、その内容がBinlog_do_db/Binlog_ignore_dbの欄に表示されます。特に指定していない場合は全てのデータベースがバイナリログの対象となります。
mysql> SHOW MASTER STATUS\G
*************************** 1. row ***************************
File: mymaster-bin.004
Position: 135
Binlog_do_db:
Binlog_ignore_db:
1 row in set (0.01 sec)
| 項目名 | 内容 |
|---|---|
| File | 使用中のバイナリログのファイル名。 |
| Position | 使用中のバイナリログの位置情報。 |
| Binlog_do_db | バイナリログに記録するように指定されているデータベース名。 |
| Binlog_ignore_db | バイナリログに記録しないように指定されているデータベース名。 |
SHOW MASTER LOGS
古いものも含めて、現在マスタに存在する全てのバイナリログのファイル名が表示されます。実行結果は図16のようになります。
mysql> SHOW MASTER LOGS; +------------------+ | Log_name | +------------------+ | mymaster-bin.001 | | mymaster-bin.002 | | mymaster-bin.003 | | mymaster-bin.004 | +------------------+ 4 rows in set (0.00 sec)
バイナリログは延々と増えていくので、定期的に削除しなければなりません。しかし、むやみに削除するとレプリケーションが崩れてしまうので、後述するSHOW SLAVE STATUSで処理済みのバイナリログのファイル名を確認して削除します。スレーブが複数台ある場合は、安全に削除できるのは全てのスレーブで処理済みとなっているバイナリログである点に気をつけてください。また、削除にはファイルシステム上のファイルを直接削除するのではなく、マスタでPURGE MASTERLOGS文を発行して削除します。例えば、
PURGE MASTER LOGS TO 'mymaster-bin.003';
を実行した場合は、mymaster-bin.003は残り、それより古いmymaster-bin.002と001が削除されます。RESETMASTER文でもバイナリログの削除ができますが、この文を実行すると全てのバイナリログをマスタから削除するのでレプリケーションが崩れてしまいます。レプリケーションの運用中は、RESET MASTERではなくPURGE MASTER LOGSを使ってバイナリログを削除しましょう。
スレーブの状況確認
次はスレーブの状況を確認するためのSQL文です。
SHOW SLAVE STATUS
図17のように、スレーブの様々な情報を確認することができます。項目の内容は表2の通りです。
SHOW SLAVE STATUSの内容はMySQLのバージョンによって度々変わるので、最新の情報はMySQL ABのリファレンスマニュアルを参照してください。
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Master_Host: mymaster
Master_User: repl
Master_Port: 3306
Connect_retry: 60
Master_Log_File: mymaster-bin.004
Read_Master_Log_Pos: 135
Relay_Log_File: myslave-relay-bin.002
Relay_Log_Pos: 668
Relay_Master_Log_File: mymaster-bin.004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_do_db:
Replicate_ignore_db:
Last_errno: 0
Last_error:
Skip_counter: 0
Exec_master_log_pos: 135
Relay_log_space: 668
1 row in set (0.00 sec)
| 項目名 | 内容 |
|---|---|
| Master_Host | マスタのホスト名。 |
| Master_User | マスタへの接続に使用するユーザ名。 |
| Master_Port | マスタのポート番号。 |
| Connect_retry | マスタと接続できなかった場合に、スレーブが再接続を試みるまでの待機秒数。 |
| Master_Log_File | スレーブのI/Oスレッドが現在処理中のマスタのバイナリログファイル名。 |
| Read_Master_Log_Pos | I/Oスレッドが読み込んだマスタのバイナリログの位置。 |
| Relay_Log_File | スレーブのSQLスレッドが現在処理中のスレーブのリレーログファイル名。 |
| Relay_Log_Pos | SQLスレッドが実行完了したスレーブのリレーログの位置。 |
| Relay_Master_Log_File | SQLスレッドが最後に実行したクエリが記録されていたマスタのバイナリログファイル名。 |
| Slave_IO_Running | I/Oスレッドが稼働中かどうか。 |
| Slave_SQL_Running | SQLスレッドが稼働中かどうか。 |
| Replicate_do_db | レプリケートするように指定されているデータベース名。 |
| Replicate_ignore_db | レプリケートしないように指定されているデータベース名。 |
| Last_errno | 最後に実行したクエリのエラー番号。『0』ならば成功。 |
| Last_error | 最後に実行したクエリのエラーメッセージなど。空文字はエラーがないことを示す。 |
| Skip_counter | 最後にSQL_SLAVE_SKIP_COUNTERを使用したときの値。使用していなければ『0』になる。 |
| Exec_master_log_pos | SQLスレッドが最後に実行したクエリの、マスタのバイナリログでの位置。 |
| Relay_log_space | 存在するリレーログファイルのサイズ。単位はバイト。 |
項目がたくさんありますが、そのいくつかについて注意点を書きます。
ログファイル名と位置情報の項目がいくつかあります。Master_Log_FileにはRead_Master_Log_Posが対応し、Relay_Log_FileにはRelay_Log_Posが、Relay_Master_Log_FileにはExec_master_log_posが対応します。
I/Oスレッドが正常動作していればSlave_IO_Runningが『Yes』に、SQLスレッドが正常動作していればSlave_SQL_Runningが『Yes』になっています。どちらか片方でも『Yes』ではない場合は、レプリケーションは『止まっている』状態となりますので、スレーブの動作を監視する場合はこの項目を確認すればよいでしょう。
Last_errorにはエラーログファイルに記録されるようなエラーメッセージも表示されるので、Last_errnoが正常を示す『0』でも、Last_errorにはエラーメッセージが表示されている、ということがあり得ます。スレーブの状態を監視する際は、片方だけでなく、Last_errnoとLast_errorの両方を確認しましょう。
遅延時間の確認
正しくレプリケーションが行われていても、MySQLは非同期のレプリケーションなので、どうしても更新がスレーブに反映されるまでに遅延が発生してしまいます。
とはいえ遅延時間が極端に大きい場合はどこかに異常がある可能性が高いので、遅延時間がどの程度なのか確認するための方法を考えてみます。
測定用のテーブルを使う
まずはこんな方法です。遅延測定用のテーブルを作り、マスタで定期的にこのテーブルの日付型のカラムを更新します。スレーブでは定期点にこのカラムの値を参照して、遅延時間を測定します。
例えば、図18のようにテーブルを作ってデータを追加してから、図19のクエリを定期的に発行するプログラムをマスタ側で動かします。
mysql> CREATE TABLE rep_delay (update_date TIMESTAMP); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO rep_delay VALUES (NULL); Query OK, 1 row affected (0.01 sec)
UPDATE rep_delay SET update_date = NULL;
一方、スレーブでは図20のようなクエリを発行して、遅延時間を秒単位で知ることができます。
SELECT NOW()-update_date AS delay FROM rep_delay;
気を付けなければならないのは、マスタとスレーブの時刻が同期していないと測定した遅延時間に誤差が生じる点です。MySQLに限らず、サーバを管理する場合はログのタイムスタンプなども重要となる場合があるので、NTPなどで時刻同期しておきましょう。
もう一つ。気づかれていると思いますが、実はこの方法では正確な遅延時間は計れません。最大で、マスタで測定用のUPDATE文を実行する間隔の時間は測定値のブレとして許容しなければなりません。では間隔を短くすればよいかというとそういうわけでもなく、短くしすぎると測定用のクエリがサーバに大きな負荷をかける恐れがあります。適切な測定間隔にして、測定値がブレを大幅に越えるようならば警告を発する、というような監視プログラムにすればよいでしょう。
バイナリログの位置情報を使う
次にバイナリログの位置情報を使った確認方法を考えてみます。
まずはSHOW SLAVE STATUSのRead_Master_Log_PosとExec_master_log_posに注目します。これらは共にマスタのバイナリログでの位置情報で、それぞれスレーブのI/Oスレッドがマスタから読み込んだ位置、スレーブのSQLスレッドが実行した位置を示す項目でした。つまり、この2つの値が同じならば、I/OスレッドとSQLスレッドとの間には遅延がないことになります。
もう一つ、SHOW MASTER STATUSのPositionも考えてみます。これはマスタが最後に実行した更新系の処理の、バイナリログでの位置を示すものでした。
したがって、これら3つの値、すなわち
- SHOW MASTER STATUSのPosition
- SHOW SLAVE STATUSのRead_Master_Log_Pos
- SHOW SLAVE STATUSのExec_master_log_pos
が全て同じ値であれば、測定した時点でマスタとスレーブの間には遅延がなく全く同一のデータを持っていることになります。
別の言い方をすると、PositionとRead_Master_Log_Posが常に離れている場合は、ネットワークトラブルでマスタからスレーブへのバイナリログのコピーが遅れているなどの理由で遅延が発生していると考えることができますし、Read_Master_Log_PosとExec_master_log_posが常に離れている場合は、スレーブの更新処理能力がマスタより劣っているなどの理由で遅延が発生している、と考えることができます。
データの同一性の確認
残念ながら、マスタとスレーブの間でデータの同一性を確認する簡単な方法はありません。
しかし、各テーブルのレコード数を比較するような簡易的な確認ならば、PerlやRubyなどを使って比較的簡単に作れると思います。
トラブルシューティング
最後にレプリケーションでありがちなトラブルとその対処方法について説明します。
マスタが止まった!
マスタのmysqldが異常終了した、マスタのサーバがOSごとフリーズしたなどなどいろいろな場合が考えられますが、どの場合でも、MySQLのデータが無事であればマスタでmysqldを起動しなおすだけで自動的にスレーブと接続し、レプリケーションが再開されます。
不幸なことにMySQLのデータが破損した場合は、基本的にスレーブの設定を変更してスレーブをマスタに昇格すればよいでしょう。単純なマスタ1台、スレーブ1台の構成の場合は、復旧作業として行うべき事はそれほど多くはありませんが、突発的な障害対応は手練の管理者でも動揺するものです。ましてやそれがとても大切なデータの場合はなおさらです。必ず試験環境で復旧手順の確認と、焦っていても読み違えることがないような簡潔な手順書、自動化できる手順はスクリプトを書いておくなど、障害発生時の備えをしておきましょう。
スレーブが止まった!
スレーブのmysqldが何らかの原因で停止した場合は、マスタと同じように、データに破損がない限りはmysqldを起動しなおせばレプリケーションが再開されます。
mysqldは正常に稼働しているが、スレーブでのレプリケート処理が停止した場合は、基本的に停止した原因を取り除いてからスレーブでSTART SLAVE文を実行して再開します。この場合の具体例をいくつか見てみましょう。
スレーブのI/Oスレッドが止まった場合
経験的にI/Oスレッドが単独で停止することは稀だと思いますが、もし停止してしまった場合は、スレーブのエラーログやSHOW SLAVE STATUS文のLast_errorを確認して原因を調べます。
I/Oスレッドが停止すると、スレーブでは更新処理が発生しなくなります。この『更新処理が発生しない状態』に聞き覚えはないでしょうか。そう、スナップショットをとるときにマスタに対して行ったことです。
I/OスレッドはSTOP SLAVE文で明示的に止めることができるので、レプリケートしていれば、マスタに影響することなくスレーブからスナップショットをとってバックアップや新たなスレーブを追加する際の初期データとして活用することができます。これも知っておいて損はない、レプリケーションのメリットの1つでしょう。
スレーブのSQLスレッドが止まった場合
SQLスレッドが止まってしまう原因はいろいろと考えられます。
例えば、誤ってスレーブにレコードをINSERTしてしまい、そのレコードが原因で、マスタでは完了したクエリがスレーブではUNIQUE制約のために実行できなかった、などが考えられます。
この場合、スレーブのエラーログやSHOW SLAVE STATUS文のLast_errorを確認して原因を取り除きます。先の例だと、スレーブからマスタと重複するレコードをDELETE文で削除します。
原因を取り除いたら、START SLAVE文でSQLスレッドを開始します。
mysql> START SLAVE SQL_THREAD; Query OK, 0 rows affected (0.02 sec)
もし、エラーとなったクエリが無視してよいものならば、SET GLOBAL SQL_SLAVE_SKIP_COUNTER文を使ってクエリをスキップしてSQLスレッドを再開することもできます。
SQLスレッドが停止する原因となったクエリを1つスキップしてSQLスレッドを再開するには以下のようにスレーブで実行します。
mysql> SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1; Query OK, 0 rows affected (0.00 sec) mysql> START SLAVE SQL_THREAD; Query OK, 0 rows affected (0.00 sec)
いずれの場合も、START SLAVE文を発行したあとにSHOW SLAVE STATUSでSQLスレッドの状態を確認しましょう。
レプリケーション環境下で実行してはいけないSQL
実行するとレプリケーションが停止してしまうSQLがあります。 ここではどんなSQLを発行してはいけないかを具体的に説明します。 あわせてMySQL ABのドキュメントも参照してください。
対象が不定になる更新系のクエリ
以下のようなクエリは更新対象が不定になるので、
UNIQUE制約違反を引き起こしレプリケーションの停止を招く可能性があります。
UNIQUE制約違反がその場で発生せず、
後日たまたま重複するINSERTを行ったらレプリケーションが止まったり、
レプリケーションは動いているのに実はデータが一致していないということになりうるので注意が必要です。
- UPDATE table SET col1 = 'foo' LIMIT 1;
- LIMITで抽出される行がマスタとスレーブとで同一とは限りません。 LIMITが必要な場合は、UNIQUEなカラムでORDER BYを使って同順となるようにします。
- REPLACE ... SELECTもしくはINSERT ... SELECT
- これらのSQLで、 更新対象のテーブルのプライマリキーがAUTO_INCREMENTで、かつ、 SELECT文にORDER BYを使っていない場合に、 REPLACEもしくはINSERTされる順が不定となるため、AUTO_INCREMENTで発番されるプライマリキーがマスタとスレーブとで異なってしまいます。
ユーザ変数を使用する更新クエリ
MySQLのドキュメントによれば、ユーザ変数を使用した更新クエリのレプリケーションは4.1からの対応となっています。ですので以下のようなクエリは4.0では正しくレプリケートされません。
SELECT @winner:=id FROM user ORDER BY point DESC LIMIT 1; UPDATE user SET point = point + 10 WHERE id = @winner;
レプリケーションに関するMySQL 5.0以降での変更点
5.1
- ステートメントベースに加え、行ベースのレプリケーションに対応
- SHOW SLAVE STATUSにいくつか項目が追加された
特にSeconds_Behind_Masterが有益で、レプリケーションがどのぐらい遅延しているかの指標に使えます。
5.5
nippondanjiさんのすばらしいまとめ記事の「レプリケーションの機能拡充!」の項に変更点が列挙されています。
おわりに
MySQLのレプリケーションの特徴やセットアップの方法を見てきました。レプリケーションときくとなんとなく敷居が高いイメージがありますが、特に新規の場合のセットアップは拍子抜けするほど簡単で、その割には得られることはいろいろとあります。
また、安定性も高く、障害検知など足りない機能を補ってやれば、十分に実用レベルに達した品質のデータベースシステムを構築することができると思います。
先日、MySQL Cluster (NDB Cluster)というものが 発表されました。
これはその名の通りMySQLを使ったクラスタシステム で、 - 高可用性 - スケーラビリティ - 高性能 - 低コスト がウリとされています。
しかもMySQLと同じGPLと商用ライセンスのデュアル ライセンスなので、無料で利用できソースコードも読 むことができます。
レプリケーションと比較すると、その構成、設定共 に複雑ですが、止められないデータベースシステムを 構築する場合は試してみる価値はあるでしょう。
参考文献
-
![エキスパートのためのMySQL[運用+管理]トラブルシューティングガイド](http://ecx.images-amazon.com/images/I/41oqE-9dM2L._SL80_.jpg) 『エキスパートのためのMySQL[運用+管理]トラブルシューティングガイド』,
『エキスパートのためのMySQL[運用+管理]トラブルシューティングガイド』,
奥野 幹也, 技術評論社, 2010/6/12 - nippondanjiの二つ名でも知られる奥野さんが書いた、タイトル通り運用と管理の現場のノウハウがギュっと詰まった書籍。
-
 『現場で使える MySQL (DB Magazine SELECTION)』,
『現場で使える MySQL (DB Magazine SELECTION)』,
松信 嘉範, 翔泳社, 2006/3/17 - MySQLの技術コンサルティングをしている松信さんが書いた、全MySQL DBA必読の書。特に日本語処理の章とDBAの部はかなりお世話になりました。 出版年が若干古く、対象バージョンも4.0, 4.1, 5.0で5.1が入っていませんが、基本的なところはさほど変わっていないので、まだまだ現役で使える書籍。
 『Linux-DB システム構築/運用入門 (DB Magazine SELECTION)』,
『Linux-DB システム構築/運用入門 (DB Magazine SELECTION)』,
松信 嘉範, 翔泳社, 2009/9/17- これも松信さんの本。高可用性やハードウェアも意識したチューニングなどなどコアな話題がたくさん。先の『現場で使える MySQL』を読了した DBA はあわせて読みたい。
 『実践ハイパフォーマンスMySQL 第2版』,
『実践ハイパフォーマンスMySQL 第2版』,
Baron Schwartz Peter Zaitsev Vadim Tkachenko Jeremy D. Zawodny Arjen Lentz Derek J. Balling, オライリージャパン, 2009/12/14 (原書は 2008/06)-
チューニング、レプリケーション、バックアップと、ざっくりいうと上記2冊の本−日本語処理周辺の話題、といった内容だけど、細かいところでどっちかにしか書いてないことがあったりするので、松信さんの2冊に加えて、手元に置いておきたい本。
ぼくは特に、InnoDBのクラスタードインデックスの仕組みを理解するのにお世話になりました。 ちなみに、原書が出版されたのは5.1がRCの頃です。
変更履歴
- 2009-06-22
- 4.0系ベースの文章なので、設定レベルでは情報が古い旨を冒頭に追記。
- 2006-03-16
- レプリケーション環境下で実行してはいけないSQLにユーザ変数について追記。
- 2005-09-21
- レプリケーション環境下で実行してはいけないSQLを追記。
- 2005-09-20
- 校正前の原稿を整形して公開。
- 2004-09
- 初出:技術評論社刊『WEB+DB PRESS Vol.22』
目次
他コンテンツ
- home
- はじめに
- 書き物類
- はじめに
- スケーラブルWebシステム工房
- 現場指向のレプリケーション詳説 - mysql
- USBをシリアルコンソールに
- Debian woodyをkernel 2.6にするメモ
- kernelイメージから設定情報を取り出す
- AWStatsの検索文字列の文字化けを解消
- 現場指向のレプリケーション詳説 - mysql
- コード
- mregexp - MySQLで日本語の正規表現を扱う
- kcode - 各種文字コードを表示する

